When a disruptive event strikes—be it a cyberattack, a natural disaster, or a critical system failure—the ability to recover quickly is what separates a resilient business from one facing catastrophic losses. To ensure this resilience, organizations must have a clear and enforceable understanding with their service providers about recovery expectations. This is precisely where a well-defined Disaster Recovery Service Level Agreement Template becomes an indispensable tool, serving as the blueprint for business continuity by codifying commitments, responsibilities, and performance metrics for restoring critical operations.
A Service Level Agreement (SLA) is a formal contract that establishes a set of deliverables that one party has agreed to provide another. In the context of disaster recovery (DR), this agreement goes beyond typical uptime guarantees. It focuses specifically on the performance and timeliness of recovery processes during and after a disaster. The SLA sets measurable benchmarks, such as how quickly systems must be restored and how much data loss is permissible, providing a framework for accountability. Without this formal document, recovery efforts can dissolve into chaos, with unmet expectations, finger-pointing, and significant delays that compound the initial damage.

The consequences of operating without a robust DR SLA are severe. Ambiguity leads to disputes. When a disaster occurs, there is no time to debate who is responsible for what or argue over acceptable recovery timelines. These details must be ironed out in advance. A lack of a clear agreement can lead to extended downtime, irreversible data loss, financial penalties from regulatory non-compliance, and lasting damage to a company’s reputation. Customers, partners, and stakeholders rely on service availability, and a failure to recover effectively can shatter that trust.

This guide delves into the essential elements of a disaster recovery SLA, explaining the critical components that form the foundation of a strong agreement. We will explore key metrics like Recovery Time Objective (RTO) and Recovery Point Objective (RPO), discuss how to customize a template to fit your specific business needs, and highlight common pitfalls to avoid. By understanding these principles, you can transform a generic template into a powerful, actionable document that truly safeguards your organization against the unexpected.
What is a Disaster Recovery Service Level Agreement?
A Disaster Recovery Service Level Agreement (DR SLA) is a formal contract between an organization and its service provider that outlines the specific terms, conditions, and metrics for restoring IT infrastructure, applications, and data following a disruptive event. The provider can be an external third party, such as a Disaster-Recovery-as-a-Service (DRaaS) vendor, or an internal IT department providing services to other business units. Its primary purpose is to eliminate ambiguity by creating a shared understanding of recovery performance expectations.
Unlike a standard IT service SLA that focuses on day-to-day operational metrics like network uptime or help desk response times, a DR SLA is activated only when a declared disaster occurs. It is laser-focused on the promises made regarding the recovery process. This includes defining what constitutes a “disaster,” the specific services and systems covered under the plan, and the precise, measurable objectives that the provider must meet to restore business operations.

The core of a DR SLA is accountability. It translates an organization’s business continuity goals into legally enforceable technical requirements. For example, a business might determine it can only survive four hours of downtime for its e-commerce platform. The DR SLA would then contractually obligate the service provider to restore that platform within a four-hour window. This document ensures all parties—from IT administrators to business leaders and third-party vendors—are aligned on priorities, roles, and responsibilities before a crisis hits.

Core Components of a Comprehensive Disaster Recovery Service Level Agreement Template
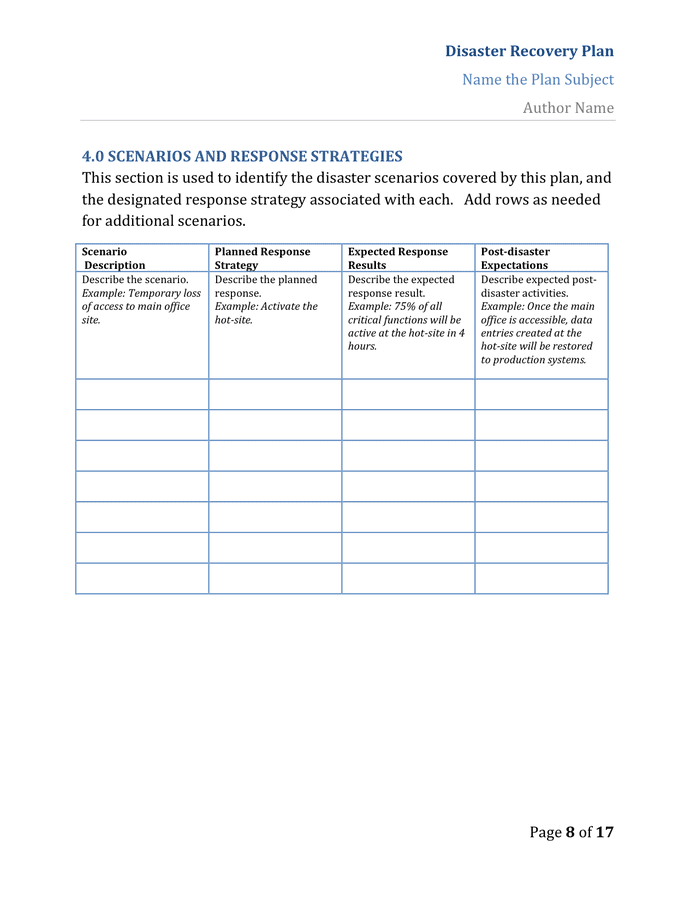
A generic template is a great starting point, but its real value comes from its detailed and customized components. A robust DR SLA must be specific, measurable, and comprehensive, leaving no room for interpretation during a crisis. Below are the essential sections that every effective agreement must include.
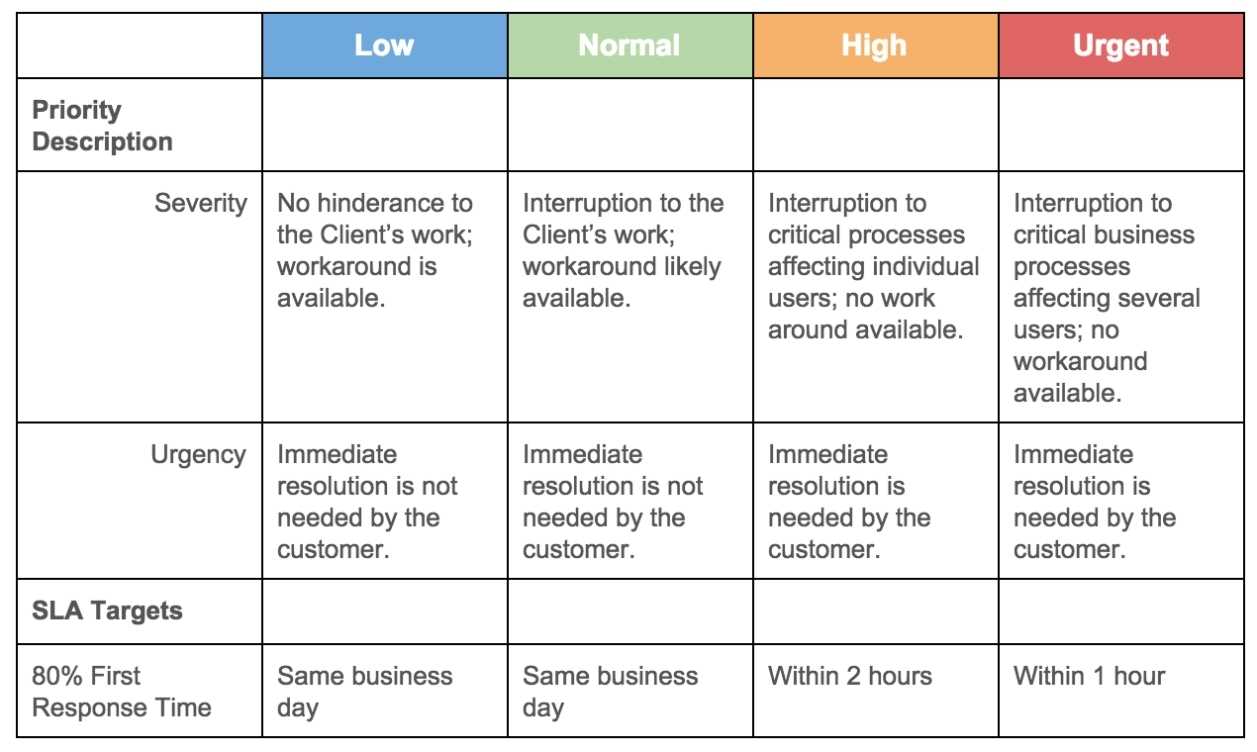
Scope of Services
This is arguably the most critical section. It must explicitly state which systems, applications, data, and infrastructure are covered by the SLA. Ambiguity here is a recipe for failure. It’s best practice to categorize assets into tiers based on their criticality to the business.

- Tier 1: Mission-critical applications that are essential for business survival (e.g., e-commerce sites, core financial systems). These will have the most aggressive recovery objectives.
- Tier 2: Business-critical systems that are important but can tolerate slightly longer downtime (e.g., internal CRM, email).
- Tier 3: Non-critical applications with more lenient recovery requirements (e.g., development environments, archival systems).
The scope should also define what constitutes a “disaster” or a “triggering event” that activates the SLA. This could range from a full data center outage to the loss of a single critical application.

Recovery Time Objective (RTO)
The Recovery Time Objective (RTO) is the maximum acceptable duration of time that a specific application or system can be offline following a disaster. It essentially answers the question: “How quickly must we be back up and running?” RTO is not about how long it takes to fix the problem, but how long it takes to restore the service, often by failing over to a secondary site. A separate RTO should be defined for each application tier. For example, a Tier 1 application might have an RTO of one hour, while a Tier 3 application might have an RTO of 24 hours.

Recovery Point Objective (RPO)
The Recovery Point Objective (RPO) defines the maximum acceptable amount of data loss, measured in time. It answers the question: “How much data can we afford to lose?” An RPO is determined by the frequency of data replication or backups. For instance, if data is replicated every 15 minutes, the RPO is 15 minutes. This means that in a worst-case scenario, up to 15 minutes of transactions could be lost. Like RTO, RPO must be defined for each application tier, as the tolerance for data loss will vary significantly across different business functions.

Roles and Responsibilities
During a crisis, clear lines of authority and communication are paramount. This section should explicitly detail the responsibilities of both the client and the service provider. It should outline:
- Declaration Process: Who has the authority to declare a disaster and initiate the recovery plan?
- Communication Plan: Who needs to be notified, and how will communication be handled among teams, executives, and even customers?
- Escalation Procedures: What is the chain of command if recovery objectives are not being met?
- Specific Tasks: A checklist of tasks and who is responsible for each, such as network configuration, data validation, and bringing services back online for end-users.
Testing and Drills
An untested DR plan is not a plan—it’s a theory. The SLA must mandate a regular testing schedule to validate that the agreed-upon RTOs and RPOs can be met. This section should specify:

- Frequency: How often will tests be conducted (e.g., annually, semi-annually)?
- Type of Tests: Will they be tabletop exercises, partial failover tests, or full failover simulations?
- Success Criteria: What defines a successful test? This should be tied directly to meeting the RTO and RPO metrics.
- Reporting: How will test results be documented and shared? The process for addressing any failures or shortcomings discovered during a test should also be included.
Penalties and Remedies
To be enforceable, an SLA must have consequences for non-performance. This section, often called “service credits” or “penalties,” outlines what happens if the provider fails to meet the agreed-upon RTO or RPO. Penalties are typically financial and may come in the form of a credit on the next month’s invoice. The penalty amounts should be significant enough to incentivize the provider to meet their obligations. This section may also include exit clauses that allow the client to terminate the contract for repeated or severe failures.

Understanding RTO and RPO: The Heart of Your DR SLA
While every component of a DR SLA is important, the Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are its foundational pillars. These two metrics dictate the entire architecture of a disaster recovery solution, directly impacting its cost, complexity, and capabilities. A misunderstanding or miscalculation of RTO and RPO can render the entire agreement ineffective.

RTO dictates the speed of recovery. It is a measure of time. An RTO of zero means services must be available continuously with no downtime, a requirement that necessitates expensive, high-availability solutions like active-active data centers. An RTO of 4 hours, on the other hand, allows for a more traditional failover process.

RPO dictates the tolerance for data loss. It is also a measure of time, but it looks backward from the moment of disaster. An RPO of zero means no data loss is permissible, which requires synchronous data replication technology. An RPO of 24 hours means the business is willing to lose up to a day’s worth of data, a scenario that can be supported by nightly backups.

The relationship between these metrics and cost is direct and exponential. The closer RTO and RPO are to zero, the more expensive the DR solution becomes. This is why a one-size-fits-all approach is impractical. A business must carefully analyze its different functions to assign appropriate—and affordable—RTOs and RPOs. This is achieved through a Business Impact Analysis (BIA), which identifies critical processes and the financial and operational impact of their disruption over time. The results of the BIA provide the data needed to tier applications and set realistic recovery objectives in the SLA.
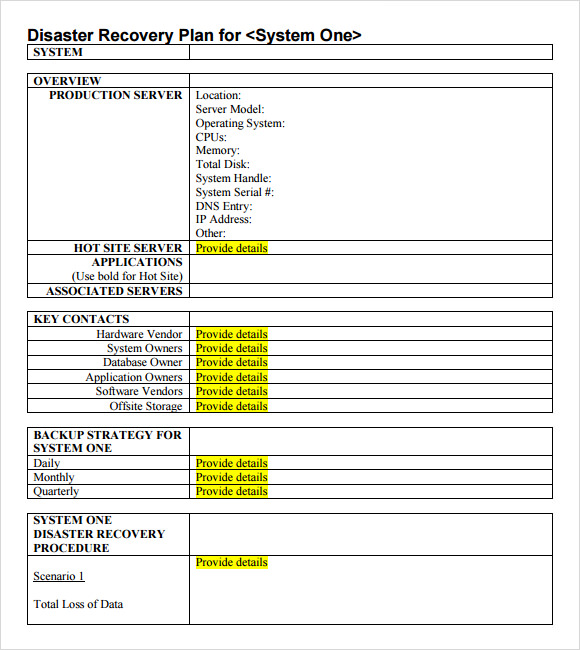
How to Customize and Implement Your Disaster Recovery Service Level Agreement Template
A template provides structure, but it cannot understand your business’s unique needs. Customizing a Disaster Recovery Service Level Agreement Template is a critical process that aligns the document with your specific operational realities and risk tolerance.

Step 1: Conduct a Business Impact Analysis (BIA)
Before you can define recovery objectives, you must understand the impact of downtime on your organization. A BIA is a systematic process to identify and evaluate the potential effects of a disruption on critical business operations. It helps you prioritize functions, identify dependencies between systems, and determine the maximum tolerable downtime (which informs your RTO) and maximum data loss (which informs your RPO) for each function.

Step 2: Identify and Classify Assets
Using the insights from the BIA, create a comprehensive inventory of all IT assets—applications, servers, databases, and network components. Classify each asset into recovery tiers (e.g., Tier 1, 2, 3) based on its business criticality. This tiered approach allows you to invest your DR resources strategically, applying the most robust and expensive solutions to the assets that matter most.
Step 3: Negotiate with Your Provider
Armed with your BIA data and asset classification, you can have an informed discussion with your DR provider. Do not simply accept their standard SLA. Use your specific RTO and RPO requirements as the basis for negotiation. Discuss the scope of services, testing procedures, and penalties for non-compliance. A reputable provider will be willing to work with you to create a customized SLA that meets your needs.
Step 4: Define Testing Procedures and Success Criteria
Collaborate with your provider to define a clear and mutually agreed-upon testing plan. Specify the frequency, scope, and methodology for DR drills. Crucially, define what constitutes success. A successful test isn’t just about failing over; it’s about failing over within the RTO specified in the SLA and ensuring data integrity is consistent with the RPO.
Step 5: Regular Review and Updates
A DR SLA is not a “set it and forget it” document. Your business is dynamic—new applications are deployed, infrastructure changes, and business priorities shift. The SLA must be a living document that evolves with your organization. Schedule regular reviews (at least annually) to ensure it remains aligned with your current business requirements and technology environment. Major changes, like a cloud migration or the launch of a new product line, should trigger an immediate review of the SLA.
Common Pitfalls to Avoid When Using a Template
While templates are useful, they can also lead to critical oversights if not used carefully. Being aware of common pitfalls can help you create a more effective and enforceable agreement.
-
Vague and Ambiguous Language: Avoid subjective terms like “best effort,” “promptly,” or “as soon as possible.” An SLA must be built on specific, measurable metrics. Replace “prompt recovery” with “a Recovery Time Objective of 4 hours.” Every key term and commitment should be clearly defined.
-
Ignoring Interdependencies: Modern IT environments are complex and interconnected. Recovering a web server is useless if its backend database is still offline. Your SLA must account for application dependencies and ensure that entire technology stacks are recovered in the correct order to restore business functionality.
-
Insufficient Testing: The single biggest mistake is having a DR SLA on paper that has never been validated in a real-world test. Regular, rigorous testing is the only way to build confidence that the provider can deliver on their promises. Insist on full failover tests, not just tabletop exercises.
-
Undefined Scope: A common point of conflict during a disaster is a disagreement over what is covered. Be granular in the “Scope of Services” section. List specific servers, applications, and datasets. If it’s not explicitly listed in the SLA, assume it’s not covered.
-
Failing to Update the Agreement: An outdated SLA is a dangerous liability. As your business evolves, the SLA must be updated to reflect new systems, retired applications, and changing business priorities. An annual review should be considered the bare minimum.
Conclusion
A well-crafted Disaster Recovery Service Level Agreement is more than just a legal document; it is a cornerstone of operational resilience and a critical component of any comprehensive business continuity strategy. It transforms vague promises of recovery into specific, measurable, and enforceable commitments. By clearly defining scope, setting firm Recovery Time Objectives and Recovery Point Objectives, and mandating regular testing, a DR SLA ensures that all stakeholders have a unified understanding of what to expect when a disaster strikes.
Using a Disaster Recovery Service Level Agreement Template is an excellent way to begin the process, providing a structured framework that covers the essential elements. However, the ultimate success of the agreement hinges on thoughtful customization. Through a diligent process of business impact analysis, asset classification, and negotiation, a generic template can be tailored to reflect the unique needs and risks of your organization.
Ultimately, proactive planning is the key. Waiting for a disruptive event to discover gaps in your recovery plan is a risk no business can afford to take. By investing the time and effort to create a robust and regularly validated DR SLA, you build a foundation of accountability and preparedness that can mean the difference between a swift recovery and a devastating failure.
]]>


